
In today’s healthcare landscape, organizations rely on data across the care continuum with patient data playing an important role in the care they receive. Inaccurate and low-quality information can impact patient safety and lead to unnecessary testing or improper treatment and medication management. According to Black Book Research, inaccurate patient identification and patient matching issues—which lead to repeated medical care due to duplicate records—cost hospitals an average of $1,950 per patient per stay and more than $800 per ED visit.
As the wearable device market evolves, machine-generated IoT data is also adding to the already large volume of data from legacy sources. This can complicate efficiency and effectiveness of data analysis to support value-based healthcare.
Master data management (MDM) technology helps solve those challenges. The MDM process involves aggregating, matching, cleansing, rationalizing, and distributing master data throughout an enterprise to ensure consistent and controlled usage of information for core business activities.
Benefits of master data management
Well-implemented, up-to-date MDM capabilities can help organizations:
- Use data in downstream applications or analytics solutions to increase patient engagement, reduce the cost of care, and improve overall population health.
- Increase health information organizations (HIOs) trust in data by making sure it’s consistent, deduplicated, and standardized to support critical decisions.
- Speed up claims processing and reduce follow-ups that impact member and provider experiences.
MDM is critical for sourcing and displaying accurate patient information, which can improve care coordination and help providers and patients achieve better outcomes.
Master data management at Innovaccer
It’s vital to implement and regularly enhance appropriate MDM capabilities to improve accuracy and efficiency of these solutions. Innovaccer’s Data Activation Platform (DAP) manages both identity and reference data. Here’s how:
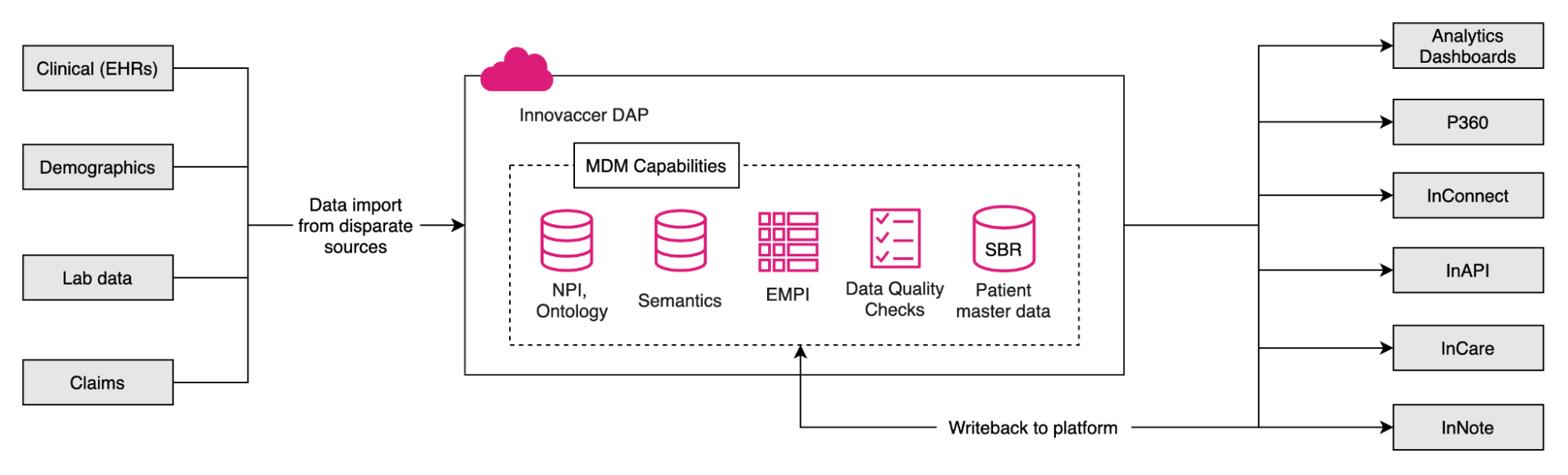
Identity data management
Identity data management refers to managing the master data of patients, providers, and location identifiers.
- EMPI: An enterprise master patient index (EMPI) provides a unique identifier for each patient that can be used by other systems or applications. Matching algorithms are used to consolidate records from disparate sources and create a master record after deduplicating data like name, date of birth, gender, SSN, and more.
As data from various sources is ingested to the DAP, records and rows are matched based on a tree-based approach, in which nodes act as a matcher on column attribute and a match score is assigned. By comparing the match score with threshold values, the DAP decides tree traversal to the next node. As the records are matched to patients, a relevant EMPI is assigned. If there’s no match, a new EMPI is assigned to the patient. Deviations from a configured logic in the workflow are queued for data engineers who remediate data and merge or assign it to different EMPIs. Patient activity is then recorded by associating with respective EMPI. - SBR: The single best record (SBR) of a patient is the best record created based on all activity linked to an EMPI. As patient activity increases over time, the volume of duplicate and semantically and syntactically different data increases. Matching and merging this aggregated data from multiple data warehouses can be challenging.
Legacy matching algorithms (i.e., probabilistic and deterministic matching) help with deduplication on frequently changing information like address, email, phone number, etc., but they’re time-consuming and not highly accurate.
Consider the example below with semantically and syntactically different aggregated patient data. This unstandardized and duplicate data can negatively impact user experiences and lead to communication barriers.

Data standardization (e.g., fixing spelling errors, correcting abbreviations, formatting to meet appropriate standards) and machine learning (ML) can help clean data and improve matching accuracy. Training ML models to establish relationships between records can help save time, reduce operational costs, and improve business efficiency. This can improve the OSAT score of 360-view applications such as Innovaccer’s Patient 360 application.
Reference data management
Reference data includes healthcare terminology as well as external and internal industry standards used to aggregate data and drive meaningful analytics.
Healthcare coding system data (e.g., medication and diagnosis codes, along with their descriptions) from multiple websites is imported in various formats—Excel, ZIP, open-source APIs, or scraping—and automated to push incremental changes in a central storage. Any changes to reference data are tracked and published to internal sources. After formatting, standardization, manual validation, and data quality checks, data is moved for usage on customer tenants.
- NPI data: A National Provider Identifier (NPI) is a unique identification number for covered healthcare providers. Provider data is synced from NPI sources (NPPES and PECOS) in real-time. It is centrally maintained and serves as a reference for provider information like license number, enumeration date, entity type, gender, address, and more after data is ingested into the Innovaccer’s DAP. Deactivated NPIs are soft-deleted and respective deactivation dates are captured. All downstream apps that require PCP information can retrieve details from internal NPI data.
- Ontology data: Ontology data includes common, linkable vocabularies like CD, CPT, HCPCS, SNOMED, RxNorm, NDC, Medispan, CVX, MVX, Taxonomy, LOINC, and more. This data is maintained internally and referenced for semantic consistency. Mapping of updated code sets ensures data is compliant with updated ontology and end-to-end data lineage is maintained (e.g., ICD-9 to ICD-10, SNOMED to ICD-10 mappings). It is useful to make data understandable and useful for both medical professionals like physicians and non-professionals like patients who are not familiar with scientific texts.
- Semantic data: Gender, marital status, language, religion, and other standard codes from HL7, ISO, etc. are ingested and maintained in the DAP. Aggregated data from multiple sources is normalized by referring to semantic data, which enables interoperability and ensures multiple systems can understand and interpret data in the same way.
Write-back to platform
Innovaccer’s DAP has the ability to integrate patient data from internal sources using REST APIs. The data from Patient 360, InNote, and CMS applications is ingested back to the platform to be shared with other applications through dashboards or exposed via FHIR APIs.
To see DAP in action,book a demo.


