In healthcare, clear communication between providers, patients, and care teams is essential. Capturing who says what in conversations, from physician-patient interactions to care manager outreach, is critical for accurate clinical documentation, better patient outcomes, and operational efficiency.
At Innovaccer, we have developed a state-of-the-art diarization backend service that accurately identifies and separates speakers in healthcare conversations, even when audio is processed in multiple segments. This breakthrough powers our Ambient AI capabilities, transforming how healthcare conversations are transcribed and analyzed.
What Is Speaker Diarization, And Why Is It Important in Healthcare?
Speaker diarization is the process of determining “who spoke when” in an audio recording. In clinical settings, it helps distinguish between the voices of doctors, patients, nurses, and support staff. Accurate diarization ensures:
- Precise clinical notes reflecting each speaker’s contributions
- Better context for decision-making and follow-up care
- Enhanced compliance with documentation and billing standards
Innovaccer’s Diarization Backend: How It Works
Our diarization service leverages advanced open-source and proprietary technologies to ensure consistent, accurate speaker identification throughout a conversation, even when audio is processed in discrete chunks.
Step 1: Audio Processing and Parallel Requests
The backend receives audio from our agent executable. If diarization is enabled, the system simultaneously sends the audio to both:
- A transcription service that converts speech to text with precise word timestamps
- A diarization API that splits audio into speaker-specific segments
Step 2: Speaker Segmentation with Pyannote and SpeechBrain
The diarization API uses the pyannote.audio library, powered by the speechbrain model, to segment the audio by speaker. If a speaker appears multiple times, their segments are grouped and merged into a longer clip to improve accuracy.
Step 3: Speaker Embeddings via NVIDIA NeMo
Each speaker’s audio segment is converted into a unique embedding using NVIDIA NeMo. These embeddings act as audio “fingerprints” that represent the speaker’s voice characteristics.
Step 4: Speaker Consistency with Redis and Threshold Matching
Our system maintains a Redis database of speaker embeddings for each call session. When a new segment arrives, it compares the embedding against stored ones, calculating a similarity score based on audio length and other parameters.
- If the new segment matches an existing speaker beyond a dynamic threshold, labels are updated for consistency.
- If not, and the maximum number of speakers isn’t exceeded, a new speaker label is created.
- If the speaker limit is reached, the new segment is matched with the closest existing speaker.
- If the stored audio sample is short, we append new incoming samples that have a strong dBFS value and high similarity to the existing sample. This helps build a more complete and reliable stored sample for accurate comparison.
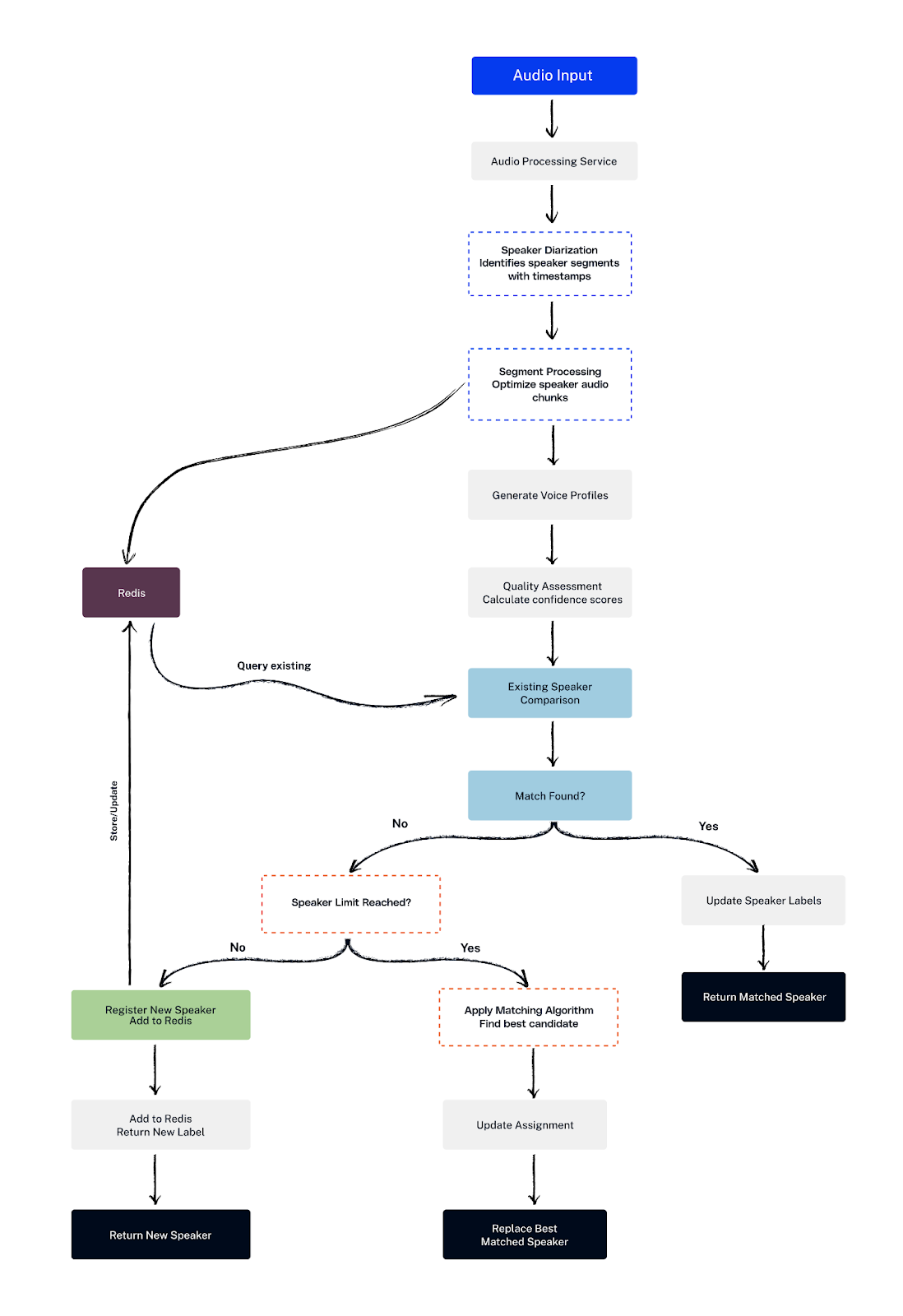
This ensures consistent speaker labeling across multiple audio chunks, even if the speaker’s speech is intermittent.
Step 5: Merging Transcription and Diarization Outputs
Finally, the backend merges the transcription’s word timestamps with the diarization’s speaker timestamps, producing a clear transcript with labeled speaker turns. For example:
speaker_1: “Hello, I am calling from XYZ Healthcare.”
speaker_2: “Hi, thanks for calling.”
Flexible API for Integration
Our diarization backend exposes a simple POST API where clients can send audio files or bytes along with parameters like minimum and maximum expected speakers and a unique call ID. The API returns detailed speaker segments with start and end times, loudness (dBFS), and metadata for each chunk, supporting robust integration with healthcare workflows.
Why Innovaccer’s Diarization Matters for Healthcare
- Improved Clinical Documentation: By accurately identifying speakers, our AI reduces manual transcription errors, improving the quality and usability of clinical notes.
- Enhanced Patient Experience: Clear records of conversations help providers understand patient needs better and follow up appropriately.
- Scalable Across Settings: Whether it’s telemedicine, in-person visits, or care coordination calls, this diarization backend supports diverse healthcare scenarios.
- Supports Compliance and Billing: Reliable speaker labeling supports audit trails, coding, and regulatory requirements.
- Real-Time Audio Feedback for Improved Call Quality: dBFS values and speaker labels help identify low volume in real time, guiding agents or patients to speak louder for better audio quality.
Innovaccer’s innovative diarization technology is a critical pillar in advancing Ambient AI solutions for healthcare. By ensuring every voice in a conversation is accurately captured and attributed, we empower providers with actionable insights—making every healthcare conversation count.