This is the third post in a four-part series on Sara SLMs: 12 purpose-built small language models for clinical extraction, care documentation, and revenue cycle.Read part one here|Read part two here.
A care manager's day is measured in calls. On a full schedule, they might move through 12 to 15 patient interactions with only a few minutes between each. In those minutes, they need to absorb months of clinical history that includes active diagnoses, current medications, open care gaps, SDOH flags, the last protocol engagement and what came up on the previous call. They need to know what to ask before the patient picks up.
After each call, the clock starts again. Five sections of call notes. Assessment fields. Care plan updates. Protocol step closures. All of it before the next name appears in the queue.
That time pressure isn't incidental. It's the defining constraint of care management work. And it's almost entirely documentation, not clinical judgment, not relationship-building. Documentation.
Sara-Care is a suite of eight fine-tuned models built to handle that work before calls, during calls, and after calls, so that care managers can spend the time they recover on the patients in front of them.

Eight models to handle admin work
Sara-Care SLMs is split into two distinct suites, each built for a different part of the job.
Thedocumentation suite handles the structured work that wraps every patient interaction. Four models, each fine-tuned on MedGemma 4B, built for speed and schema reliability:
- Side Panel Patient Summary: a structured pre-call brief pulled from clinical history, current medications, open care gaps, and SDOH context. Ready before the care manager picks up the phone.
- Call Transcript Summary: a five-section structured summary generated from the call recording after the interaction, so care managers aren't writing notes while trying to listen.
- Protocol Summarization: a date-organized audit summary from protocol engagement records, giving care managers and supervisors a clean view of where each patient stands.
- Assessment Autofill: extracts answered questions directly from call transcripts and populates assessment forms automatically.
Thecare planning suite handles the harder reasoning work. Four models, fine-tuned on Gemma-31B, a larger base model than the documentation suite, because recommending a care plan for a specific patient requires more than pattern-matching on a schema.
- Gap Identification: flags open care gaps from HEDIS protocol engagement patterns.
- Goal Recommendation: generates patient-specific SMART goals calibrated to the patient's clinical profile.
- Intervention Recommendation: proposes interventions matched to the patient's barriers, acuity, and social context.
- Full Plan Generation: assembles a complete structured care plan.
The choice between 4B and 31B models wasn’t arbitrary. Documentation tasks are structured and schema-driven; the model needs to be fast and reliable. Care planning requires understanding enough clinical context to recommend something actionable for a specific patient. These are modeling problems of varying complexity, and they call for different model sizes.
This suite of SLMs are available on the Gravity platform, allowing healthcare organizations to easily associate SLMs with enterprise data and workflows and rapidly build compliant, production-ready AI agents.
Documentation suite
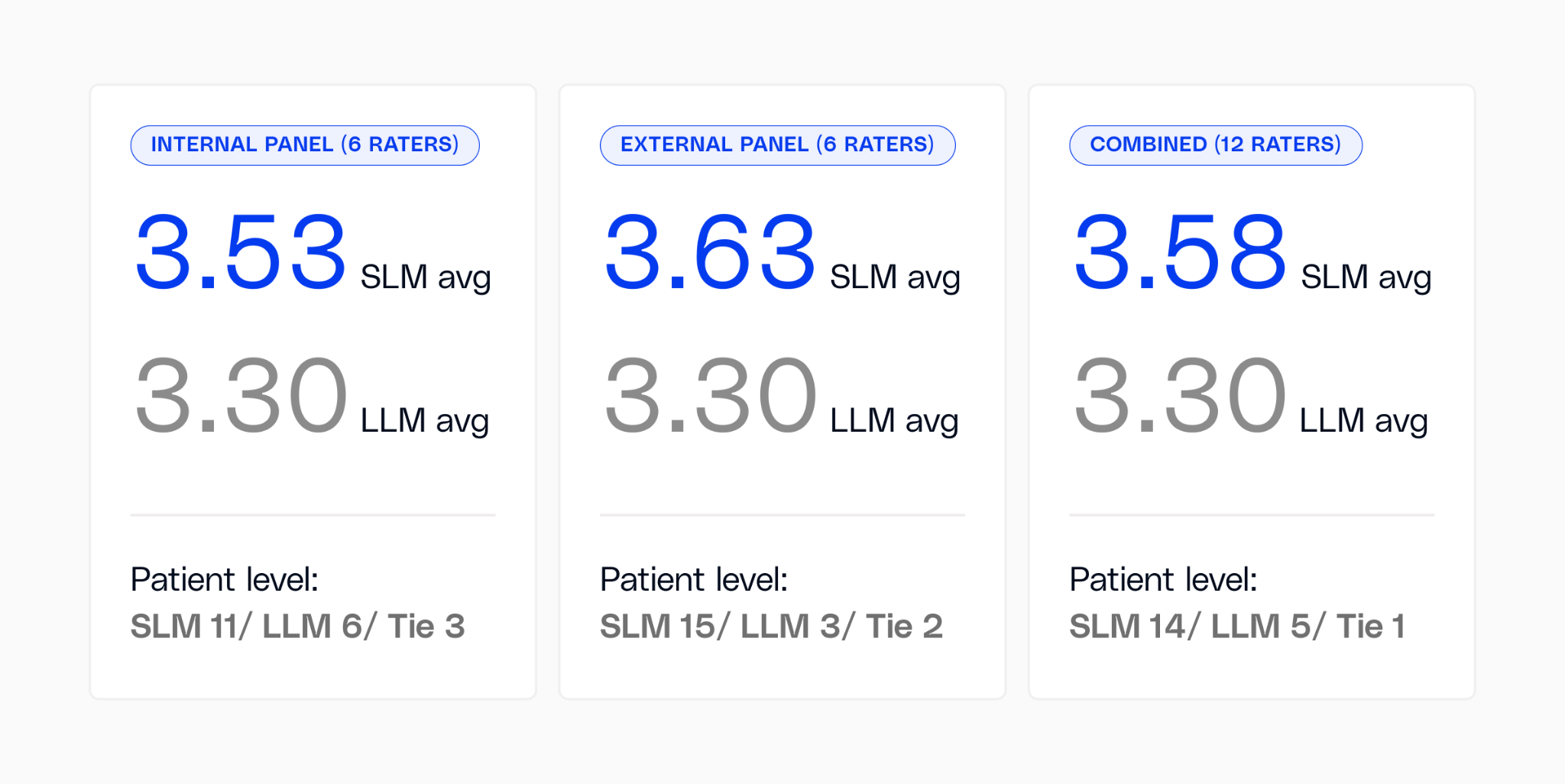
The documentation suite was evaluated head-to-head against Claude Opus 4.6, a frontier reasoning model available at the time of testing across 20 real patient cases, with 12 independent clinical raters (six internal, six external). We followed a rater-blinded evaluation protocol: outputs were anonymized, and raters did not know which output came from which model. Sara-Care won in every dimension.
Quality: Raters scored Sara-Care 3.58 vs. Claude Opus 4.6 at 3.30 on a 5-point scale.

We also used LLM as a judge to score the two summaries on a scale of 5 based on accuracy, completeness, brevity, clarity and format compliance. Sara-Care won 59% of the time with an overall score of 4.53 and Claude Opus 4.6 won 33% of the time with a score of 4.40 and 8% of the time it was a tie.
Accuracy: The most telling number was date capture accuracy which was 94.7% for Sara-Care vs. 30.7% for Claude Opus 4.6. Protocol timelines and care gap tracking are built on dates. A patient summary that gets the clinical history right but misattributes when something happened isn't a useful brief. BERTScore F1 that measures semantic fidelity came in at 0.982 vs. 0.591. Combined quantitative score which was a weighted sum of Rouge-L, TF-IDF cosine similarity and BERTScore F1 came in at 0.981 vs. 0.565.
Assessment autofill hit 97.7% question-level accuracy and 94.3% answer accuracy. Care managers spend their post-call time reviewing, not transcribing.
Speed: Time to first token was 491 ms for Sara-Care vs. 2,426 ms for Claude Opus 4.6 which was 4.9x faster. End-to-end latency was 2.1 seconds for Sara-Care vs. 4.9 seconds for Claude Opus 4.6.
Those latency numbers have a consequence that's easy to miss in benchmark tables. A brief that loads after the call starts isn't a pre-call brief. On a 15-call day, the additional wait time per interaction compounds into something you feel. And the care manager who has to wait isn't just losing time, they're starting every call slightly unprepared.
Sara-Care: Documentation Suite at a glance

Care planning suite

Evaluating the care planning suite required a different standard of proof, so we measured its reasoning capabilities transparently.
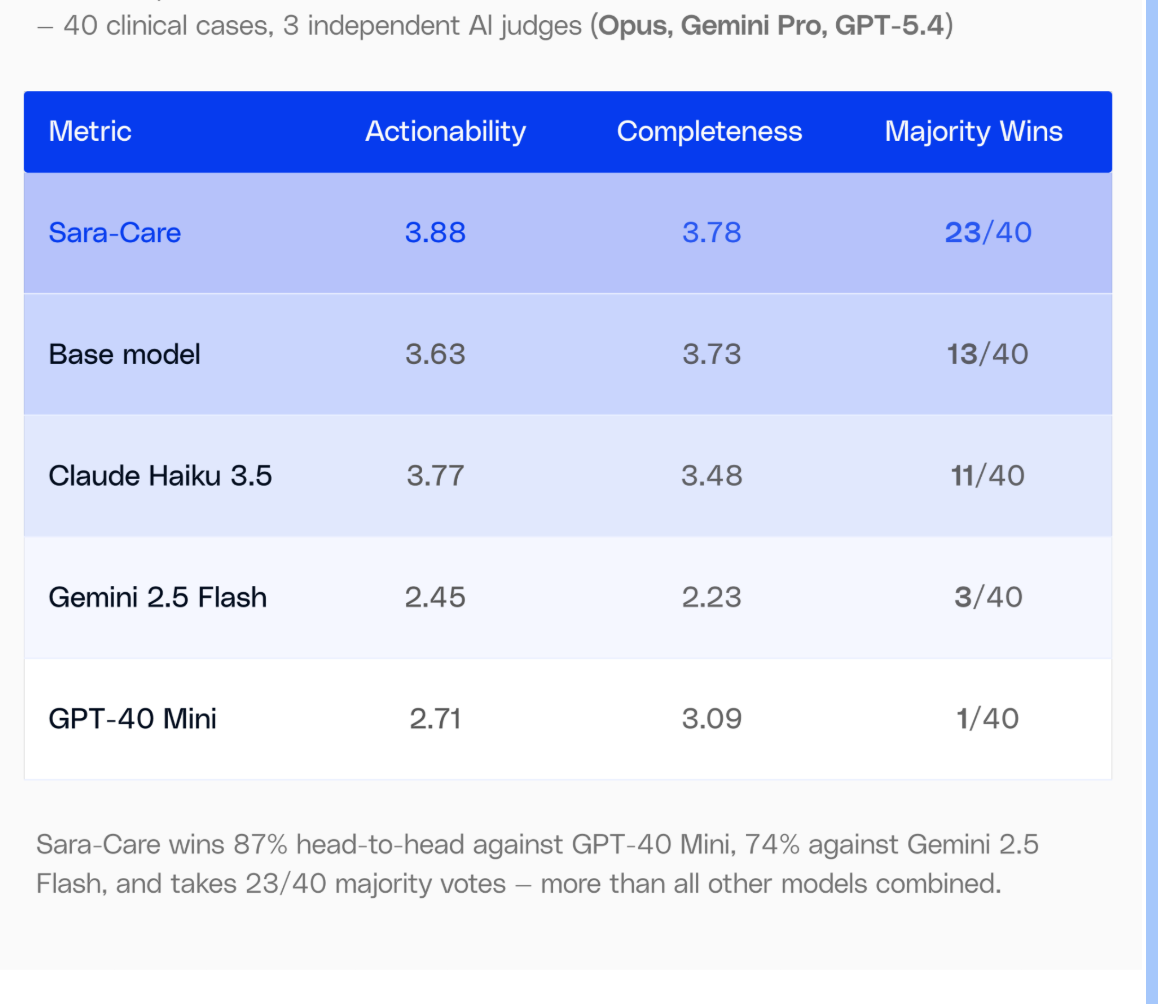
We ran a blind comparative evaluation on the care planning models: 40 clinical cases, all model outputs randomly shuffled, three independent AI judges (Claude Opus 4.6, Gemini 3 Pro, and GPT-5.4) scoring each on clinical accuracy, patient specificity, completeness, and actionability without knowing which model produced it.
Against comparable models, the fine-tuned model wins decisively. It takes 23 of 40 majority votes more than all other models combined. In head-to-head matchups, it wins 87% of the time against GPT-4o Mini and 74% against Gemini 2.5 Flash.
On actionability, the dimension that determines whether a care manager can pick up the output and act on it, the fine-tuned model scores 3.88, ahead of Haiku (3.77), the base model (3.63), GPT-4o Mini (2.71), and Gemini 2.5 Flash (2.45).
On completeness, it scores 3.78, ahead of both Sonnet (3.47) and Haiku (3.48). For a model running entirely on your infrastructure with no PHI leaving your environment and no external API dependency, those are meaningful numbers.
While frontier models like Claude Sonnet 4 currently represent the ceiling for complex clinical reasoning (scoring 4.22 overall compared to our 3.47), the gap is closing at an unprecedented rate. Frontier models still maintain an edge in patient specificity (4.75 vs. 3.51), but our trajectory tells a compelling story. Our previous generation of adapters scored 2.44. The current generation has surged to 3.85 against comparable models, improving by over a point in every dimension: accuracy +1.38, specificity +1.29, completeness +1.40, and actionability +1.58. That is a generational leap, bringing highly capable clinical reasoning directly into the workflow.
The things that matter most in production don't change: cost, latency, consistency, and keeping patient data inside your environment.
What comes next
The care planning models reason well over structured patient data. What they don't have today is access to the clinical guidelines that inform care decisions like HEDIS measures, CMS protocols, payer-specific coverage rules, organization-specific care pathways. A care manager carries that context in their head. A model doesn't.
The next phase of Sara-Care integrates the reasoning layer with clinical knowledge bases. The fine-tuned adapters handle extraction and structured output, knowing how to read a patient's history and produce a care plan in the format a care manager expects. The knowledge base provides the clinical grounding, covering which screenings are overdue by which guidelines, which interventions are evidence-supported for this condition and acuity level, and which SDOH referrals are available in the patient's geography.
This isn't retrieval-augmented generation in the generic sense. It's a deliberate separation of concerns where the model reasons over the patient, the knowledge base provides the clinical standard, and the output reflects both. The gap identification adapter already cites HEDIS measures and the knowledge base makes those citations current, organization-specific, and linked to the care manager's actual workflow. Goal and intervention recommendations improve when the model can ground its suggestions in published protocols rather than relying on what it learned during training.
The architecture is the same principle that drives Sara-Extract feeding Sara-Care: each layer does what it's good at and hands clean output to the next. The knowledge base is the next layer.
Sara-Care: Care Planning Suite at a glance
Clinical raters graded on time saved
Building Sara-Care taught us something about how care managers actually judge AI tools. Clinical raters didn't grade outputs on technical completeness. They asked one question: does this save time, or does it create a new task? Technical accuracy is only part of the solution; if a care manager has to reformat or reread the output before using it, there is still a functional gap in the workflow. The core principle that outputs must be 'ready to use' rather than 'ready to edit' drove every revision we made across all eight models. It's why the scorecard includes speed and date accuracy alongside semantic quality. A brief that's right but slow, or accurate but structured in a way that requires interpretation, doesn't clear the bar.
It's the right question to ask of any clinical AI tool.
The Quiet Failure Point of Clinical AI
Sara-Care doesn't read raw clinical notes. It reads structured data that Sara-Extract already pulled from them.
The patient summary a care manager sees before a call was assembled from diagnoses, medications, labs, and care gap data that Sara-Extract extracted and normalized. The care plan that a planning model generates is reasoning over a structured patient picture and not over a free text from an EHR. The quality of the brief, the accuracy of the plan, the completeness of the gaps flagged, all of it traces back to what the extraction layer produced upstream.
That dependency is worth sharing, because this is where a lot of clinical AI quietly breaks down. The downstream model takes the blame for a weak output when the actual problem was incomplete or inconsistent data going in. Sara-Care works because the foundation underneath it is reliable. That's not a marketing claim, it's an architectural one. The stack is only as good as what each layer hands to the next.
Next in the series: Sara SLMs for Revenue Cycle: how three fine-tuned models tackle the clinical reading comprehension problems behind $20B+ in annual denials and coding errors.